Adaptive Reasoning
We’re introducing a new default mode for Glean: Adaptive Reasoning. Adaptive mode automatically adjusts how much reasoning Glean applies to each question, so users get the right balance of speed and intelligence. We recommend adaptive mode for all users. You can toggle reasoning modes at anytime in Glean.

Waldo, Glean's agentic search model
Adaptive reasoning is driven by Waldo, Glean's agentic search model, a retrieval-optimized model that runs automatically before the frontier model on eligible queries. Waldo quickly gathers the most relevant information from your organization, passes that evidence to the frontier model, and helps the final answer be faster, better grounded, and more efficient.
In practice, Glean finds the right context first, then answers with that context second.
How adaptive reasoning works
- A user asks a question in Glean.
- Waldo determines whether the question would benefit from a retrieval plan. If so, it issues targeted searches in parallel across your organization's content using a controlled set of tools.
- The pre-collected evidence is passed to the frontier model (GPT, Claude, or Gemini), which reasons over the initial searches, does its own reasoning, and produces a grounded, cited answer.
Model usage in adaptive and auto modes
When Waldo has sufficient information to answer the question, it plans retrieval, breaks down the question, and figures out the right search tools to call. Waldo never generates user-visible text. The frontier model always runs afterward and is responsible for the final response.
Glean's universal model key currently uses GPT-5.4, a premium model, in Auto mode, but we are not currently charging for its use. Under our FlexCredits pricing, FlexCredits are consumed when a premium model is automatically selected. We may begin charging for GPT-5.4 usage in Auto in the future, and if we do, we will notify you 14 days in advance. Because we are not currently tracking this usage for billing, you may see lower usage reflected in your billing dashboard today. If a user explicitly opts to use a premium model, self-selecting GPT-5.4, it will consume FlexCredits and show up on your billing dashboard.
Benefits
- Faster answers: By front-loading retrieval, Glean spends less time searching and more time reasoning, delivering noticeably faster responses. We observed a 50% reduction in latency in our testing.
- Lower LLM costs at scale: The agentic search model reduces frontier model token consumption by handling retrieval planning more efficiently.
Performance
Waldo delivers measurable latency improvements with no regression in answer quality:
| Metric | Improvement |
|---|---|
| P25 Time to First Token | -51.0% |
| P50 Time to First Token | -51.9% |
| P75 Time to First Token | -45.8% |
| Answer quality and satisfaction | No change (neutral) |
Who is affected by adaptive reasoning
Waldo runs automatically for organizations on the Glean Universal Model Key.
Organizations on AWS or Azure, or organizations using their own LLM keys, are not affected by this change. Customers from the EU are not affected by this change.
Configuration
No configuration is required from admins or end users. Waldo runs automatically on eligible queries behind the scenes.
If a query falls outside the model's scope, it immediately hands off to the frontier model with no degradation in quality.
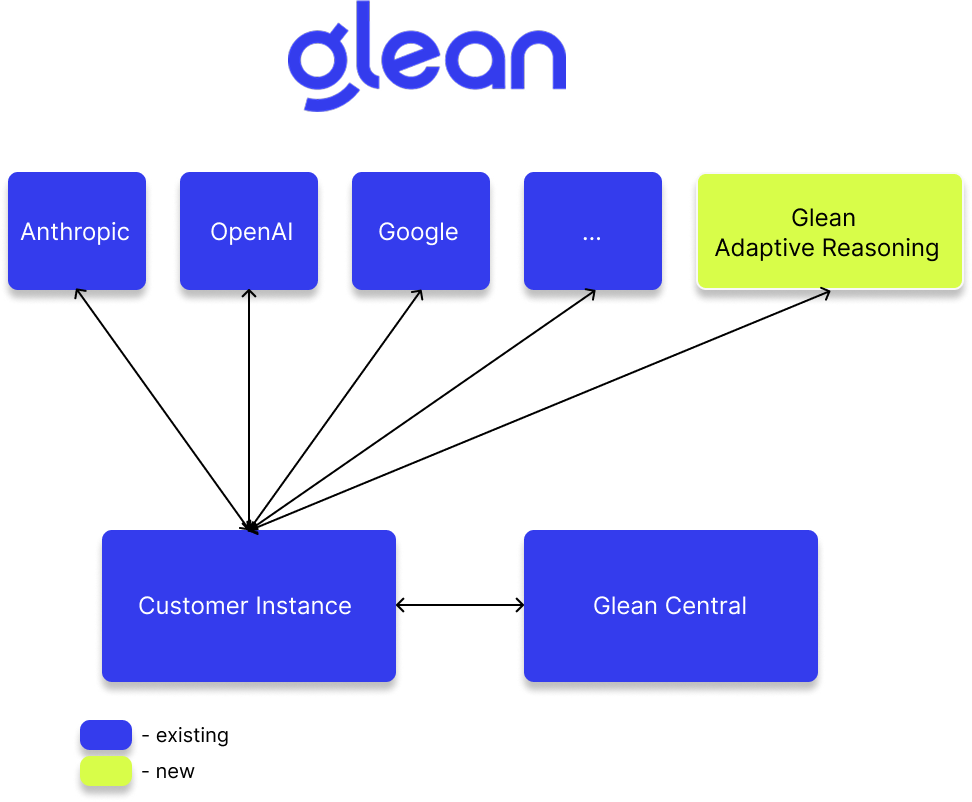
Data flow
The following describes the query processing flow for Waldo:
- User query is sent to your Glean deployment.
- Your Glean deployment calls Waldo (hosted on Glean-managed infrastructure on Google Vertex AI), executes retrieval tool calls, and collects relevant context.
- Waldo's response goes back to your Glean deployment with the retrieved tool calls and context.
- Your Glean deployment calls the frontier model. The frontier model does the rest of the reasoning for the query using the pre-collected context and generates the final response.
Model information
Waldo is built on NVIDIA's Nemotron-3 Nano (30B-A3B) model and fine-tuned by Glean using reinforcement learning. It's hosted entirely on Glean-managed infrastructure on Vertex AI in the United States and isn't served through a third-party model provider endpoint.
Customer data isn't used to train this model. The model was trained on Glean's own internal dataset of enterprise information-seeking queries.
Security and data handling
| Property | Detail |
|---|---|
| No data persistence | Query and response content is not logged in the Waldo serving path. |
| No model training on customer data | The model was trained exclusively on Glean's internal data. Your organization's data is never used to train or fine-tune the model. |
| Stateless information flows | Each call to Waldo runs independently of any other calls, reducing complexity and increasing data isolation assurance. |
| Glean-hosted and controlled | The model runs on Glean's GCP infrastructure, not a third-party endpoint. |
| US-based infrastructure | Model inference runs in Google Cloud (US region). |
| Permission enforcement | The model only retrieves content the requesting user is already authorized to access. |
| Admin controls unchanged | All existing Glean policies, including document restrictions, folder exclusions, and connector restrictions, continue to apply. |
Updated terms
Glean's AI Terms Addendum has been updated to reflect that the Service supports Glean-hosted model deployments in addition to direct third-party LLM providers. You can review the updated terms at glean.com/legal.