Memory
Memory in Glean agents lets your agent keep track of what has happened so far as it runs through its workflow. Think of memory as a notebook that your agent uses to store inputs, outputs, and important information from each step.
As your agent runs, it automatically stores the output of each step in memory. By default, each step can access the output from the immediately preceding step. You can change this setting so a step can access all previous steps, only the previous step, or no prior step outputs.
Memory building blocks: tokens
A token is the basic unit of text that the LLM processes. It is roughly analogous to a word or sub‑word fragment, for example, “un”, “break”, and “able” might each be separate tokens. When you send a prompt or receive a response, the text is first converted into a sequence of tokens, which the model then analyzes and uses to generate a response. Tokens determine how much space your input and output occupy within the memory of the agent.
Token capacity is model‑specific: each model has a maximum context window that must fit everything the agent sends and receives in a run, like the instructions and prompt, conversation history, prior step outputs, retrieved document snippets, tool inputs, and the model's own output.
To reduce latency and lower token usage, set your steps to No Prior Steps and use [[ ]] to pass only the essential data required for that specific task. You can also reference a specific step’s output or an agent input directly.
See the following provider documentation for context capacities:
| Model family | Where to find context capacities |
|---|---|
| Claude (Haiku, Opus, Sonnet) | Models overview |
| Gemini (Flash, Flash Image, Flash Lite) | Models |
| GPT | All models |
For a list of supported models, see Supported models.
How agent uses memory
When the agent runs, each step stores its outputs and any other relevant data in memory automatically. By default, a step can access the output from the immediately preceding step. If needed, you can configure a step to use all previous steps, only the previous step, or no prior step outputs.
For example, a step that sends an email can use a name collected in the immediately previous step. If the value comes from an earlier step, you can either change the memory setting or reference the output of that step directly. If you include a sub-agent as a step, its Respond step outputs are saved to memory as well, so you can use the results from the sub-agent just like results from normal steps.
How search results and documents are added to memory
-
By default, "Company search" steps retrieve "snippets" of documents, meaning they pick the most relevant parts of documents and only add those to the memory of the agent.
-
Company search can also be configured to read entire documents. This consumes a higher number of tokens, which can make the agent hit the token limit if there are a lot of searches.
-
Read document steps always read the entire contents of a document into the memory. For very long documents, this may use a lot of tokens.
-
To help prevent exceeding the token limit, agents will read only a portion of documents when the token limit is being approached. In these cases, you may see a warning similar to the image below:

How memory works
Memory works automatically within Glean agents, so you do not need to manage it manually. Each step stores its output as the agent runs. By default, the next step can access the output of the immediately preceding step. You can change the memory settings of a step to use all previous steps, only the previous step, or no prior step outputs. You can also reference the output of a specific step or an agent input directly.
If you have turned off conversation history, Glean will still retain memory for up to 2 hours. This memory is only available for follow-up tools in the agent.
Managing memory
You can control how each step in your agent uses memory. By managing memory on a per-tool basis, you decide how much information from earlier steps should be available to the AI when it carries out a specific tool. This can help your agent focus only on what is relevant, especially in complex workflows or when you want to reduce token usage.
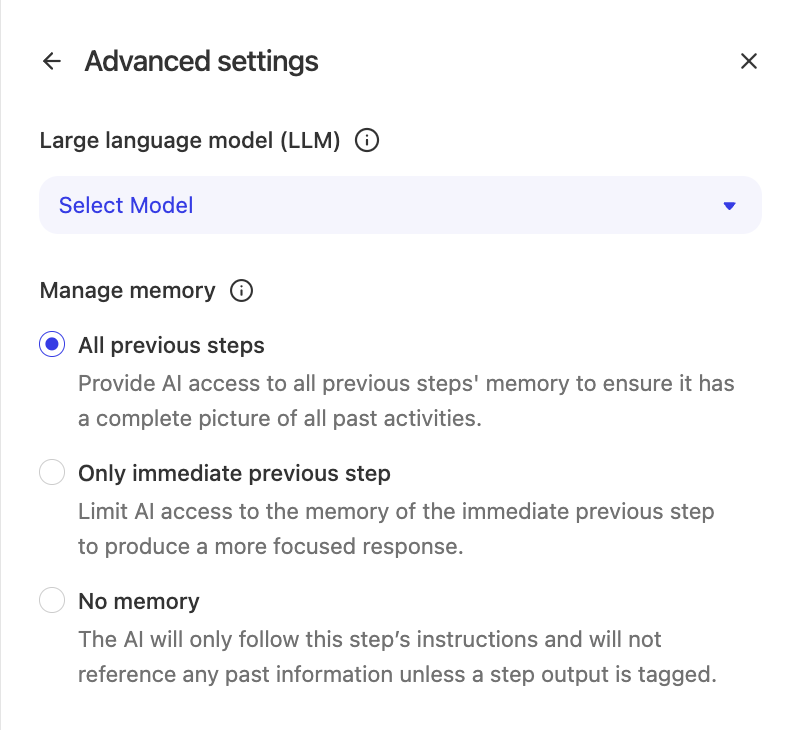
In the agent builder, select the tool you want to manage. In the menu in the upper right corner of the tool’s menu, select Advanced settings. Under the Manage memory section, select your desired memory configuration:
- All previous steps: The step can access outputs from all earlier steps.
- Previous step only: The step can access only the output from the immediately preceding step. This is the default setting.
- No prior step outputs: The step does not receive outputs from earlier steps unless you reference a specific step output or agent input directly.
Using No prior step outputs with direct references lets you pass only the context you need downstream, which can help reduce token usage.
Steps
- In the agent builder, select the tool you want to manage.
- In the menu in the upper right corner of the tool’s menu, select Advanced settings.
- Under the Manage memory section, select your desired memory configuration.
Manual referencing with snap-ins
To maintain a lean workflow, you can bypass automatic context and target specific data using the [[ ]] syntax. This allows you to reference:
- Specific step outputs: Pull data from a non-sequential earlier step.
- Agent inputs: Reference the original user prompt or initial data directly.