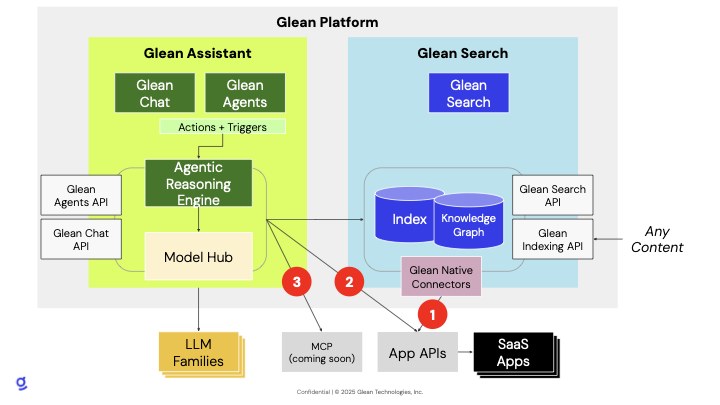
Data Flow
The Glean platform architecture consists of three primary components that work together to provide secure and effective enterprise data access:
Query Path
Handles user search requests and authentication
Data Ingestion Path
Manages data collection from enterprise sources
Data Processing Pipeline
Processes and indexes collected data
Query Path
Web Application Overview
Initial Access
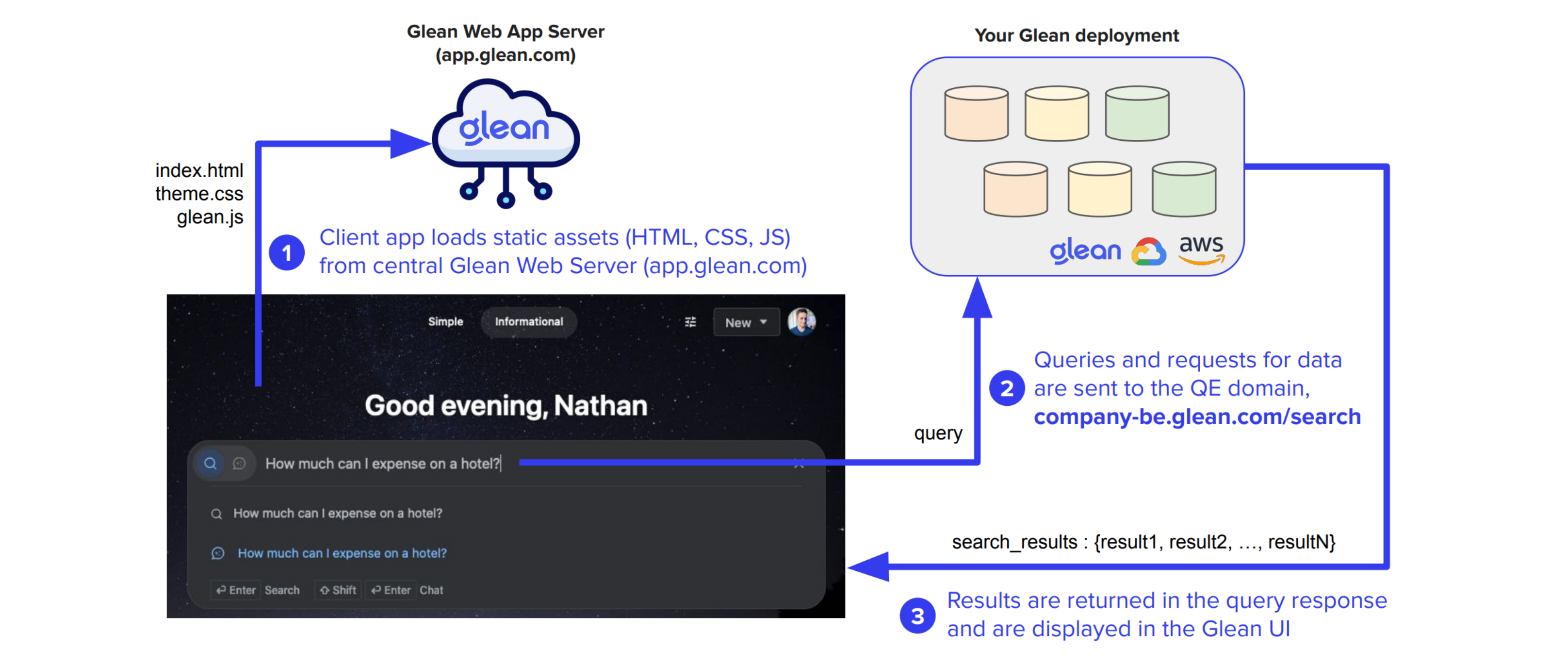
Users access Glean through the web application at https://app.glean.com, hosted within Glean's central cloud infrastructure. The application serves static assets including images, CSS, and JavaScript.
Session Check
The web client checks for an existing session state in the user's local storage. If none exists, authentication is required as anonymous searching is not supported.
Authentication Process
Users begin by entering their email address (e.g., user@company.com).
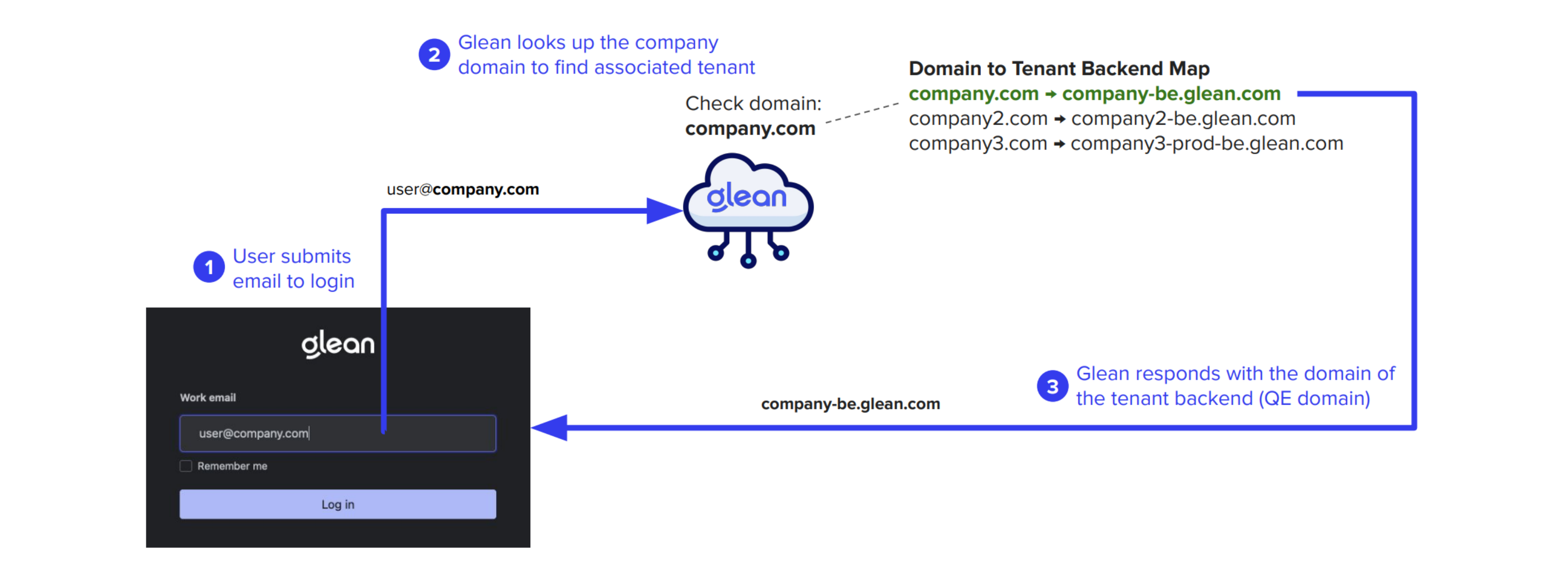
Tenant Resolution
Each customer tenant requires a list of company domain names for authentication. These domains are mapped to a tenant-specific Query Endpoint (QE) of the form <tenant_id>-be.glean.com.
The authentication process follows these steps:
Domain Lookup
When a user submits their email, the web app performs a domain lookup to determine the appropriate QE domain.
QE Assignment
The QE domain resolves to a static IP uniquely assigned to your company's Glean tenant, whether deployed in Glean SaaS or your own cloud environment.
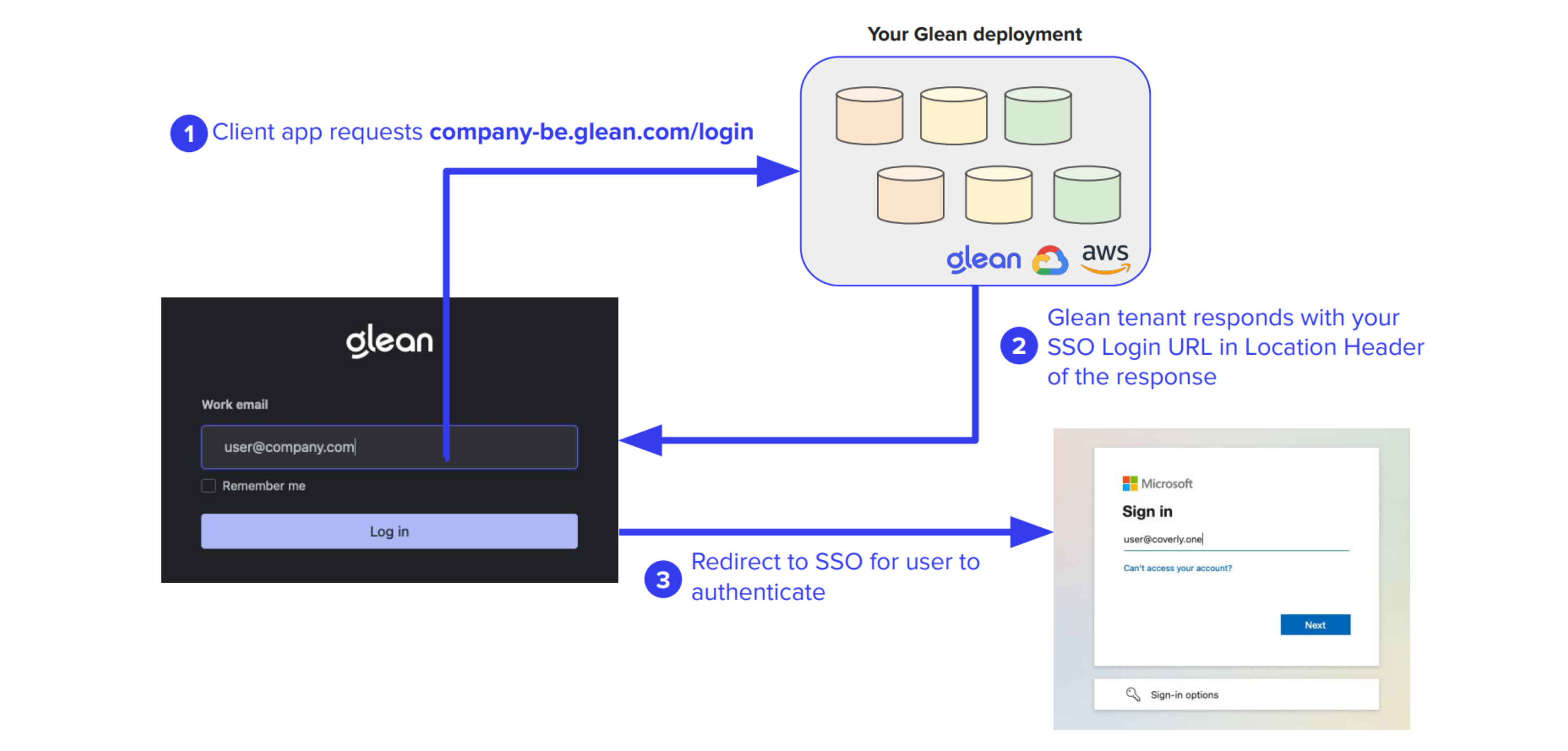
SSO Integration
Unauthenticated users are redirected to your configured SSO provider for authentication.
Authentication Flow Diagram
The following diagram illustrates the complete process from initial access to query execution:
Query Endpoint Communication
When users perform searches, requests are sent to:
https://<tenant_id>-be.glean.com/api/v1/search
API Documentation
Find detailed field descriptions in our Developer Documentation
Data Ingestion Flow
Glean's data ingestion process is built around specialized connectors deployed within your tenant's dedicated cloud project. These connectors serve multiple purposes:
Content Retrieval
Fetches content from connected enterprise sources
Activity Tracking
Monitors user interaction data
Permission Mapping
Maps and maintains access controls
Connection Methods
Data retrieval occurs via HTTPS, with two primary connection patterns depending on the connector location.
SaaS Applications
For services like Google Drive, connections occur over the public internet using HTTPS
On-Premises Systems
For internal systems like on-prem Jira, secure private connections are established via VPN or Shared VPC
Data Processing Pipelines
All data processing occurs within your tenant's project using Google Dataflow pipelines. Your data never leaves your tenant's environment.
The processing pipeline combines:
- Content from connected sources
- Permission mappings
- User data
- Activity metrics (creation, edits, views)
This combined data is then indexed to create a secure, searchable knowledge base within your tenant.
Data Ingestion Paths
Glean has three primary data ingestion paths covered below.
1. Indexing
- Description: Glean’s standard approach to ingesting unstructured and semi-structured data (e.g., documents, wikis, emails, files).
- Supported sources and examples (Google Drive, Confluence, etc.).
2. Tools
- Description: Integration of business logic and workflows via tools. Enables direct communication between Glean and third-party tools to trigger or retrieve information as needed.
- Typical use cases (ticket lookup, status update, quick access to app-level data, dynamic retrieval from data data warehouse platforms like Snowflake and Databricks).
3. Context Provisioning (MCP – Model Context Provisioning) [Upcoming]
- Description: Ability to programmatically provide context or signals to Glean without indexing content.
- Highlights dynamic context injection, such as relevant metadata or recent activity, to improve search and response.
Clarifying Glean’s Approach to Structured Data
- Glean does NOT need to ingest or index structured data from systems like Snowflake, Databricks, or other data warehouses.
- Rationale: Glean focuses on knowledge work—unstructured and conversational data—rather than analytics or raw data processing.
- Customers’ structured data in these platforms remains untouched; Glean relies on metadata/context, not direct access.
Key Takeaways for Data Ingestion Paths
- Glean ingests only what is necessary, respecting security and privacy boundaries.
- Data warehouse/BI tools (e.g., Snowflake, Databricks) are not indexed for structured datasets.
- Efficient, secure, and focused data ingestion—empowering end users without unnecessary data movement.