Add connectors

Connectors are the integrations Glean uses to crawl and index data from the platforms, services, and apps where your content lives. For an overview of how connectors work, the connector types Glean offers, and how data and permissions flow, see About connectors.
Add a connector
In the Connect connectors used across your company section, select a connector to add it to your workspace.
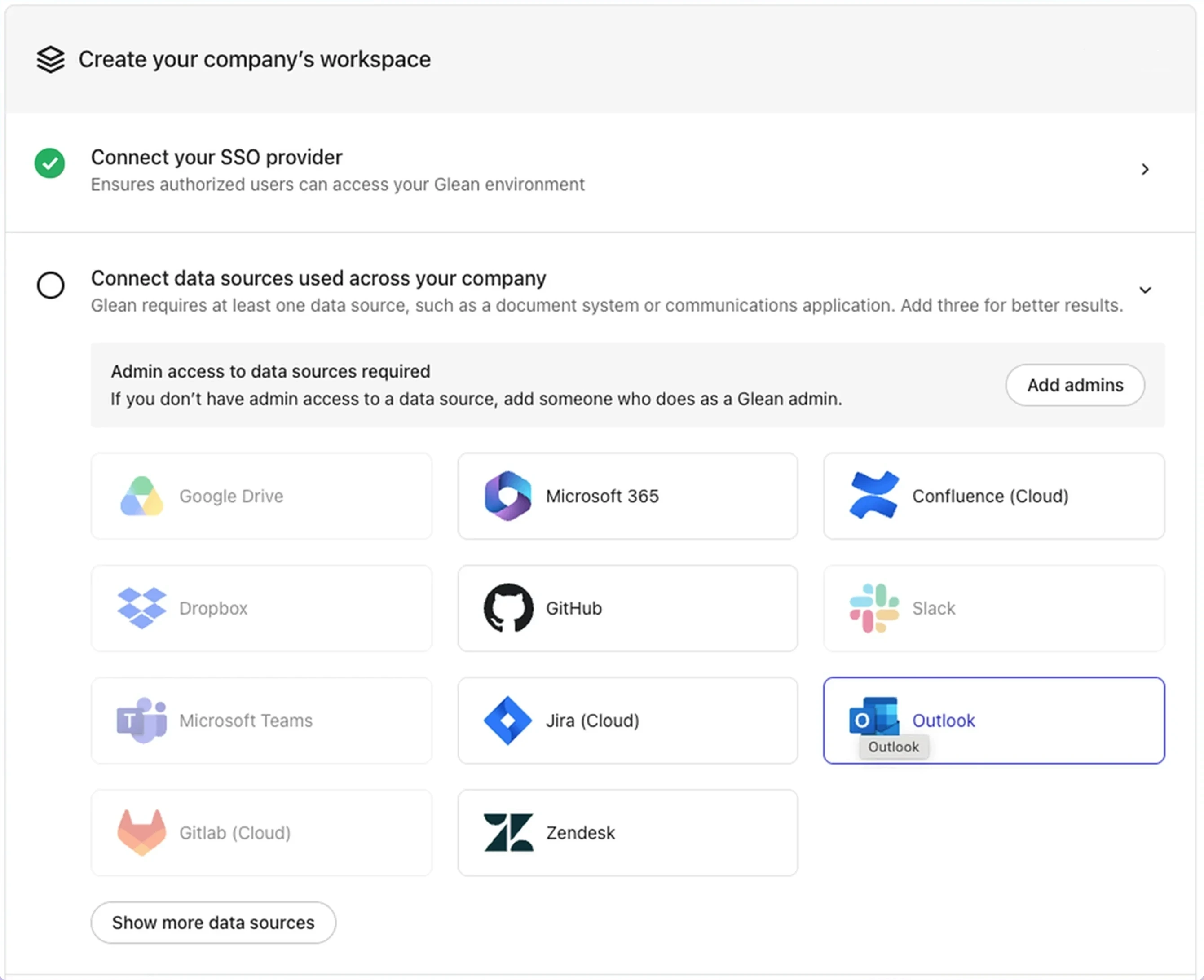
Connect connectors used across your company
Browse the Connectors hub to find the source you want to connect, then follow the connector-specific setup guide. For the end-to-end setup process — prerequisites, configuration, initial sync, and validation — see Get started with connectors.