Agentic reasoning engine
Glean recently upgraded its underlying architecture from a RAG-based system to an agentic reasoning engine, providing greater access to tools and multi-step workflows across both Glean Assistant and Glean Agents. As a result of this change we have witnessed performance increases, with an upvote rate increase of 20%, as well as token usage increases of ~50% for some customers. In this FAQ, we’ll describe why we made the changes that we did and how we see this as a long term win for our customers.
What is Glean’s agentic reasoning engine?
Glean queries were previously processed through two major steps, plan and act. The plan step was used to search and retrieve results and the act step was used to process the retrieved results and create a response for the user. However, this system limited us in our ability to resolve more complex intents as it involved only a two hops approach. As the complexity of queries in Glean increased, we realized we needed a new architecture that could handle both simple and complex, multi-step queries.
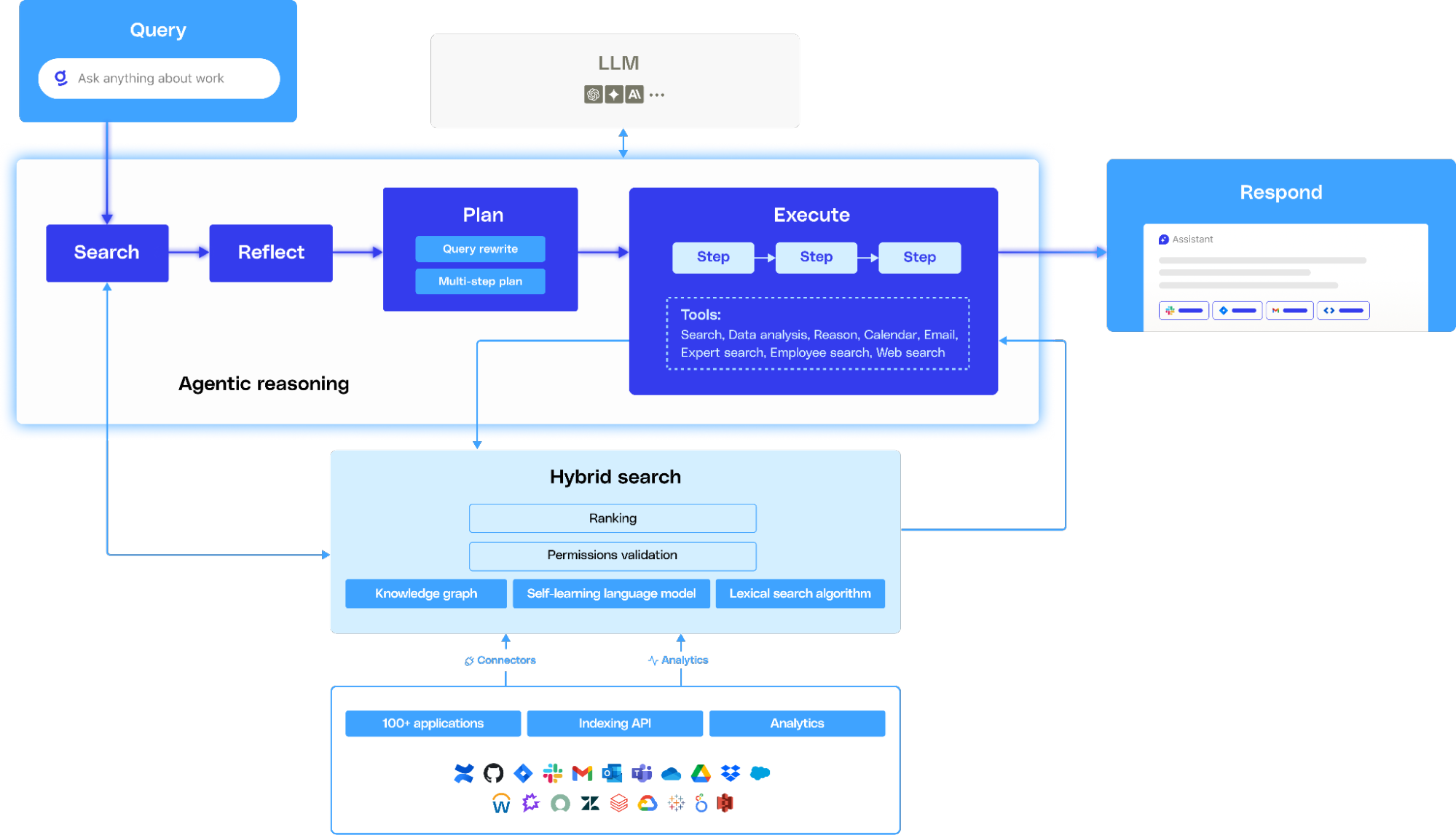
Glean now operates through two primary execution paths:
1. Fast path (info-seeking): This path is optimized for straightforward Q&A and fact-retrieval queries. It’s designed for speed and efficiency—ideal for queries that can be answered without chaining tools or invoking complex reasoning. If the system determines that a direct answer can be produced from available context or search, it will use this lightweight path.
2. Agentic path: This path is designed for queries that require deeper reasoning, multi-step execution, or tool orchestration. When invoked, the system generates a plan to fulfill the user’s intent—breaking the task into one or more steps and selecting the appropriate tools (e.g., internal search, web search, data analysis, calendar, email, expert lookup). It then executes this plan, optionally producing a final response in natural language or triggering an enterprise tool (e.g., creating a Jira ticket).
To bridge these paths, Glean includes a reflection mode. After executing the fast path, the reflection module evaluates whether the result fully answers the raw user query. If it determines the response is incomplete or inadequate, the system escalates to the agentic path, reinterpreting the user’s goal and reformulating the approach to achieve it.
As a result, we strive to balance both cost and performance. The fast-path is both intended for low latency and simple questions and the agentic path is tuned to more complex work.
New Glean capabilities with the agentic reasoning engine
Users can now run complex, multi-step queries that leverage multiple tools. Some examples are included below for reference
-
What are the key differences between various Salesforce Editions? Which edition works best for our company?
Steps needed to run the query:
- Find a list of salesforce editions
- Find details of each edition
- Compare the editions
- Summarize the differences
-
How can I help a customer who can't find the camera app on their phone, but doesn't have the option to access their account? If the customer’s problem cant be solved, open a help ticket
Steps needed to run the query:
- Consult Technical specifications of the phone
- Search for support guides
- Synthesize information
- If the user problem can be solved, create a help ticket
-
What is the distribution of components of the tickets assigned to people in my team?
Steps needed to run the query:
-
Identity the list of employees in the user’s teams
-
Find all tickets assigned to people in the team, including the relevant ticket components.
-
Analyze the ticket data to calculate the distribution of components for tickets assigned to them
-
Summarize and present the distribution of ticket components
Performance results from the agentic reasoning engine
The agentic reasoning engine has been positively received by our customer base- in-product feedback shows an increase in the upvote rate by 20% and a decrease in the downvote rate by 20%. We’ve also seen engagement with Glean increase overall by 1%- showing that better performance leads to more engagement.
We have also analyzed offline metrics using our LLM judges. These judges are focused on the metrics including completion, accuracy, and completeness. We saw 11 pp increase in completeness and 7.25 pp reduction in no answer rate. The offline metrics were computed with the agentic reasoning engine and the model upgrade from GPT-4o to GPT-4.1.
Impact on token usage
We have observed an average increase in token usage per query of ~50% across our entire customer base. Token usage increases depend on the mix of Glean queries- with simplistic information-seeking queries continuing to see faster, cheaper results.
With the agentic reasoning engine, we have also rolled out GPT-4.1 which saw improved performance results on our internal LLM evaluations. GPT-4.1 also comes with 25% lower per token pricing, partially offsetting the increase in token usage.
We understand this may be a concern for some customers. That said, we believe this new architecture unlocks a broader set of high-value use cases while aligning with industry trends—specifically, the continued decline in LLM inference costs. Combined with future improvements to our LLM routing architecture, we expect these changes to lower the overall cost of running Glean in the enterprise over time.