This page is for the Jira Cloud connector.For information on the Jira Data Center (Jira On-Prem) connector, please see the Jira Data Center Connector page.
Introduction
The JIRA connector for Glean allows Glean to fetch and index content from JIRA, ensuring users can search and access documents with authorized permissions.- Authentication: Glean requires the JIRA admin to authenticate to Glean when setting up the Glean crawler app in the Atlassian marketplace.
- Data Storage: All data is stored in the cloud project within the customer’s cloud account, ensuring no data leaves the customer’s environment
- Standard API: Glean uses Atlassian’s standard API for JIRA to ingest all data
- Content Captured: Glean captures JIRA projects, service management, dashboards, and more.
- Permissions Enforcement: Glean respects all user access permissions, ensuring users only see search results for documents they can access. When a user clicks on a search result, they are taken to the JIRA web application, which enforces the permission.
Versions Supported
The JIRA cloud connector has no specific version limitations, which is Atlassian’s SaaS offering of JIRA in the cloud. Glean supports the JIRA datacenter, a customer-managed deployment with a different connector and separate documentation.Objects Supported
The JIRA connector supports the following objects:- Projects
- Issues
- Comments
- Dashboards
- Filters
Authentication Mechanism
The Jira/Confluence admin will install an app whose installation url will be present on the Glean setup page. That will be used for indexing the content, and for webhooks .Connector credentials requirements
The JIRA connector for Glean requires specific permissions to function correctly.- Glean requires authentication to the JIRA instance to fetch relevant information.
- Glean understands all user access permissions and strictly enforces them at the time of the query, ensuring that users cannot see results to which they do not have access.
- It’s important to note that all data is stored in the cloud project in the customer’s cloud account and no data leaves the customer’s environment.
- Glean only requires READ-level permissions. Application vendors may not provide granularity in their permission schemes for read-only access as observed by Atlassian for the listing group permissions and issue securit.y
Connection instructions
Disclaimer: The instructions below are updated periodically by Glean on our customer-facing documentation. For the latest instructions, refer to the Glean Admin UIConnect to Jira Cloud
Required permissions for setup
- The user setting up this data source must have administrator permissions.
1. Set up the basics
-
Sign into Jira as an admin. Copy your Atlassian domain from the URL bar and paste into Glean:
https://YourAtlassianDomain.atlassian.net - Go to https://admin.atlassian.com/
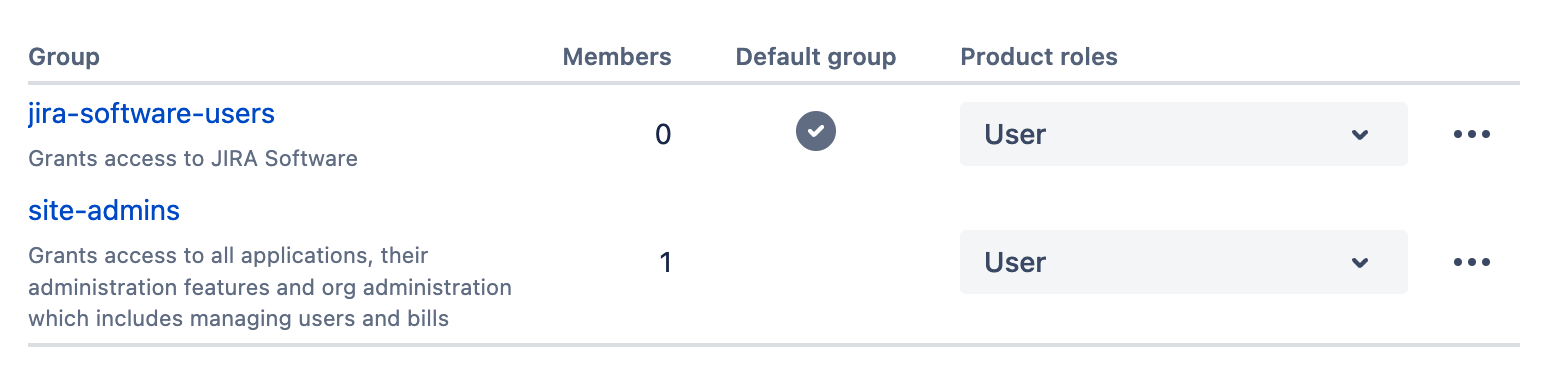
- Click the 3 dots belonging to the organization matching your Atlassian domain from step 1, then click on Manage product access
- Click on Manage access for the Jira Software Product
- Enter the default groups (there might be only one) as a comma-separated list in Glean. Only users in the provided product access groups will be able to see results in Glean.
- Click Create Forge Crawler App in Glean. This should create an installation link for the Glean crawler app.
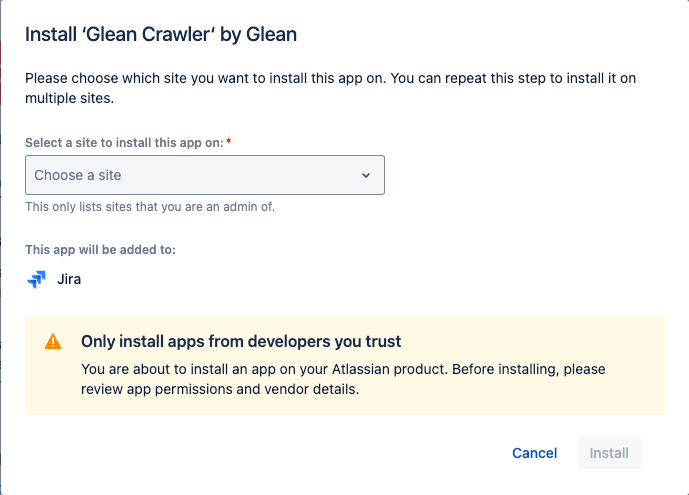
2. Connect the Forge Crawler app
- As a Jira admin, open the Forge Crawler app installation link from the Glean setup page.
- Click on Get app and install the app in the correct Jira instance.
- After the app installation is successful, click Save in Glean. You’re all set!
Authentication scope requirements
Glean requires read-only scope.Items crawled
Content Indexed
- Projects
- Issues
- Comments
- Dashboards
- Filters
Identity
- Users: Information about users within the JIRA
- Groups: Details about groups within JIRA at the global, project, and issue level
- Memberships: Information about group memberships at global and project level, indicating which users belong to which groups.
- Incremental Identity Crawls: These are performed to capture changes since the last crawl.
- Full Identity Crawls: These are conducted periodically to ensure all identity data is up-to-date.
Activity
- Adds: New issues, projects, files, or folders added
- Updates: Modifications made to existing issues, projects, files, or folders.
- Permissions Changes: Changes in issues, projects, files, or folders sharing permissions.
- Deletions: issues, projects, files, or folders that have been deleted.
- View Activity: Events indicating when an issues, projects, files, or folders has been viewed.
Rate Limits
- Queries per Second (QPS): The default rate limit is set to 12 queries.
Update frequency
Content updates for the JIRA connector in Glean can happen quite rapidly, depending on the type of update and the configuration settings. Here are the key areas:- Activity Reports: Adds, updates, and permissions changes are crawled every 10 minutes. This means that any new files, modifications to existing files, or changes in sharing permissions are detected and processed quickly.
- People / Identity Crawls: Changes to group memberships are picked up by the identity crawl, which runs every hour. This ensures that updates to user groups and their permissions are reflected promptly.
- Incremental Crawls occur every 3 hours to provide additional reliability beyond the minute-by-minute activity reports.
- Full Crawls: The frequency of full crawls can be configured, but they are generally less frequent than incremental crawls at 28 days
How the crawl works
The JIRA crawler follows the traditional crawler strategy, including utilizing the JIRA API and the following ways to get and update data:- Identity Crawl: updating and adding of People data, including users, groups, and other information
- Activity Crawl: Adds, updates, and permissions changes to content
- Webhooks: are messages sent by the application to notify Glean of changes in real-time, and then Glean either initiates crawl or picks up the change on the next crawl
- Content Crawls: Full crawls the entire defined scope of the application, whereas incremental crawls only capture the changes from the previous full or incremental crawl
Known Limitations in Crawl
- The crawl speed can be affected by the rate limits imposed by the JIRA API
- The Glean JIRA connector cannot read restricted pages unless the admin grants access to the Glean app for those pages. This means that restricted pages will not be indexed or searchable by default.
API endpoints
| Purpose | Cloud Endpoint | Cloud level Permission | OAuth 2.0 scopes required & recommended | Connect app scope required | Description |
|---|---|---|---|---|---|
| Get all dashboards | dashboard | None | Classic: read:jira-work | READ | Returns a list of dashboards owned by or shared with the user. The list may be filtered to include only favorite or owned dashboards |
| Get dashboard | dashboard/%s | None | Classic: read:jira-work | READ | Returns a dashboard for the user |
| Get users from group | group/member | Browse users and groups global permission or Administer Jira global permission | Classic: manage:jira-configuration | ADMIN | Returns a paginated list of all users in a group |
| Find groups | groups/picker | Browse projects project permission | Classic: read:jira-user | READ | Returns a list of groups whose names contain a query string |
| Get issue | issue/%s | Browse projects project permission | Classic: read:jira-work | READ | Returns the details for an issue |
| Get issue security level members | issue security schemes/%s/members | Administer Jira global permission. | Classic: manage:jira-configuration | ADMIN | Returns issue security level members: identifying which users, groups, or roles have access to issues under specific security levels within classic projects |
| Get project | project/%s | Browse projects project permission | Classic: read:jira-work | READ | Returns the project details for a project. |
| Get project issue security scheme | project/%s/issuesecuritylevelscheme | Administer Jira global permission or the Administer Projects project permission. | Classic: manage:jira-configuration | READ | allows you to understand the security configurations governing issue visibility within that project |
| Get assigned permission scheme | project/%s/permissionscheme | Administer Jira global permission or Administer projects project permission. | Classic: read:jira-work | READ | permissions granted to users and groups within a project, determining their capabilities such as issue creation, editing, or project administration |
| Get project role for project | project/%s/role/%s | Administer Projects project permission for the project or Administer Jira global permission. | Classic: read:jira-work | READ | retrieves detailed information about a particular project role within a specified project. This includes the role’s description and the list of users and groups assigned to that role, known as “actors.” |
| Search for issues using JQL | search | Browse projects project permission | Classic: read:jira-work | READ | Searches for issues using JQL |
| Get request types | servicedesk/projectKey:%s/requesttype | Permission to access the service desk | Classic: read:servicedesk-request | READ | Returns all customer request types from a service desk |
| Get request type fields | servicedesk/projectKey:%s/requesttype/field | Permission to access the service desk | Classic: read:servicedesk-request | READ | returns the fields for a service desk’s customer request type |
| Get project form index | /project/projectKey:%s/form | Permission to access the project | Classic: read:jira-work | READ | Returns all the forms associated with the project |
| Get form template | /project/projectKey:%s/form/formId%s | Permission to access the project | Classic: read:jira-work | READ | Returns the template aka schema of the form |
| Search for filters | filter/search | None | Classic: read:jira-work | READ | Returns a paginated list of filters |
| Get filter | filter/%s | None | Classic: read:jira-work | READ | Returns a filter |
| List projects | project/search | Browse Projects project permission for the project. Administer Projects project permission for the project. Administer Jira global permission. | Classic: read:jira-work | READ | Returns a paginated list of projects visible to the user |
| Access email addresses | user/email/bulk | N/A | read:email-address:jira | ACCESS_EMAIL_ADDRESSES | Returns a user’s email address regardless of the user’s profile visibility settings. For Connect apps, this API is only available to apps approved by Atlassian, according to these guidelines. For Forge apps, this API only supports access via asApp() requests. |
| Get user groups | user/groups | N/A | Classic: read:jira-user | READ | Returns the groups to which a user belongs |
| Register a webhook | Register Dynamic webhooks | Only Connect and OAuth 2.0 apps can use this operation | Classic: read:jira-work, manage:jira-webhook | READ | Registers webhooks |
Content Configuration
Note: If Inclusion (Green-Listing) options are enabled, only content from the Inclusion category will be indexed. If Exclusion (Red-Listing) options are enabled, all content in the exclusion category will be removed. If both rules are applied to the same content, then the content will not be indexed (exclusion rules take priority). The rules below should be used MINIMALLY to preserve the enterprise search experience, as most end-users expect to find all content. Most customers do not apply any rules or apply exclusion rules sparingly for sensitive folders. There may be a delay before the system fully reflects these changes. Furthermore, customers can hide the relevant documents if access has been inadvertently granted to an individual. For detailed guidance on using the “Hide” functionality via CSV upload, please refer to How to Hide Documents via CSV Upload article.Exclusion (Red-Listing) Options
By entering specific project keys in the box within the UI, the specified projects will be excluded from being crawled and indexed by Glean. Note: When you redlist a project, Glean hides that project’s content immediately. The connector will also stop crawling the project and remove already indexed content as crawls run.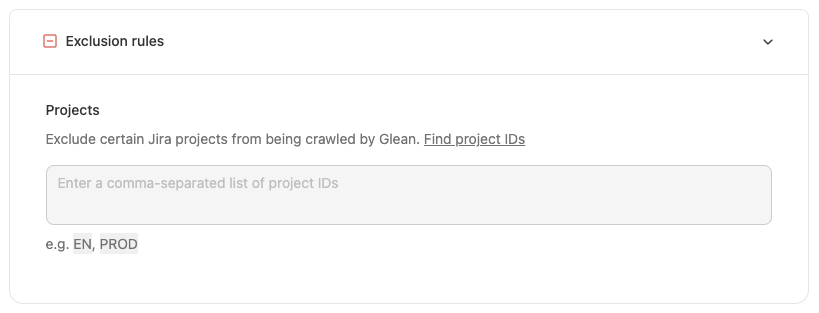
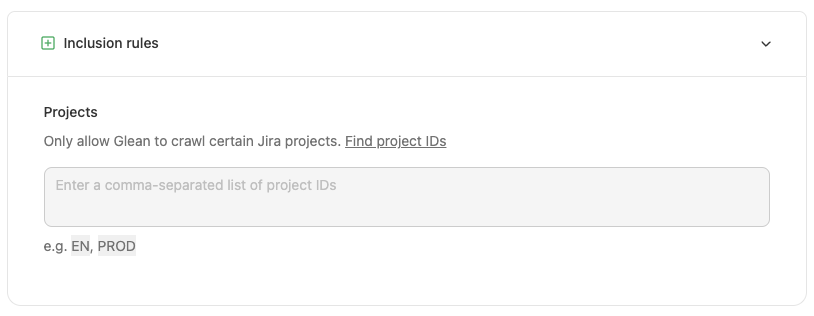
Inclusion (Green-Listing) Options
By entering specific project keys in the box within the UI, only the specified projects will be crawled and indexed by Glean. Note: When you greenlist a project, Glean starts a point crawl for that project to index it as soon as possible.