Setting up Glean to use Anthropic Claude models on Google Vertex AI
This article provides instructions for configuring Glean to use Anthropic Claude models on Google Vertex AI, allowing direct billing of LLM usage through your Google Vertex AI account using the customer key option.
Do not use this document if you are leveraging the Glean Key option. For the Glean Key option, Glean manages the configuration and provisioning of LLM resources transparently.
Enable access to models in Vertex AI
Go to the Vertex AI Model Garden and make sure you have enabled access to the following foundation models from the GCP project that Glean is running in:
| Model name | How Glean uses the model |
|---|---|
Claude Sonnet 4.6 claude-sonnet-4-6-20260217 | Agentic reasoning model used for assistant and autonomous agents |
Claude Sonnet 4.6 claude-sonnet-4-6-20260217 | Agentic model used for other, more complex tasks in Glean |
Claude Sonnet 4.6 claude-sonnet-4-6-20260217 | Fast agentic model used for simpler tasks such as follow-up question generation |
Request additional quota from Vertex AI
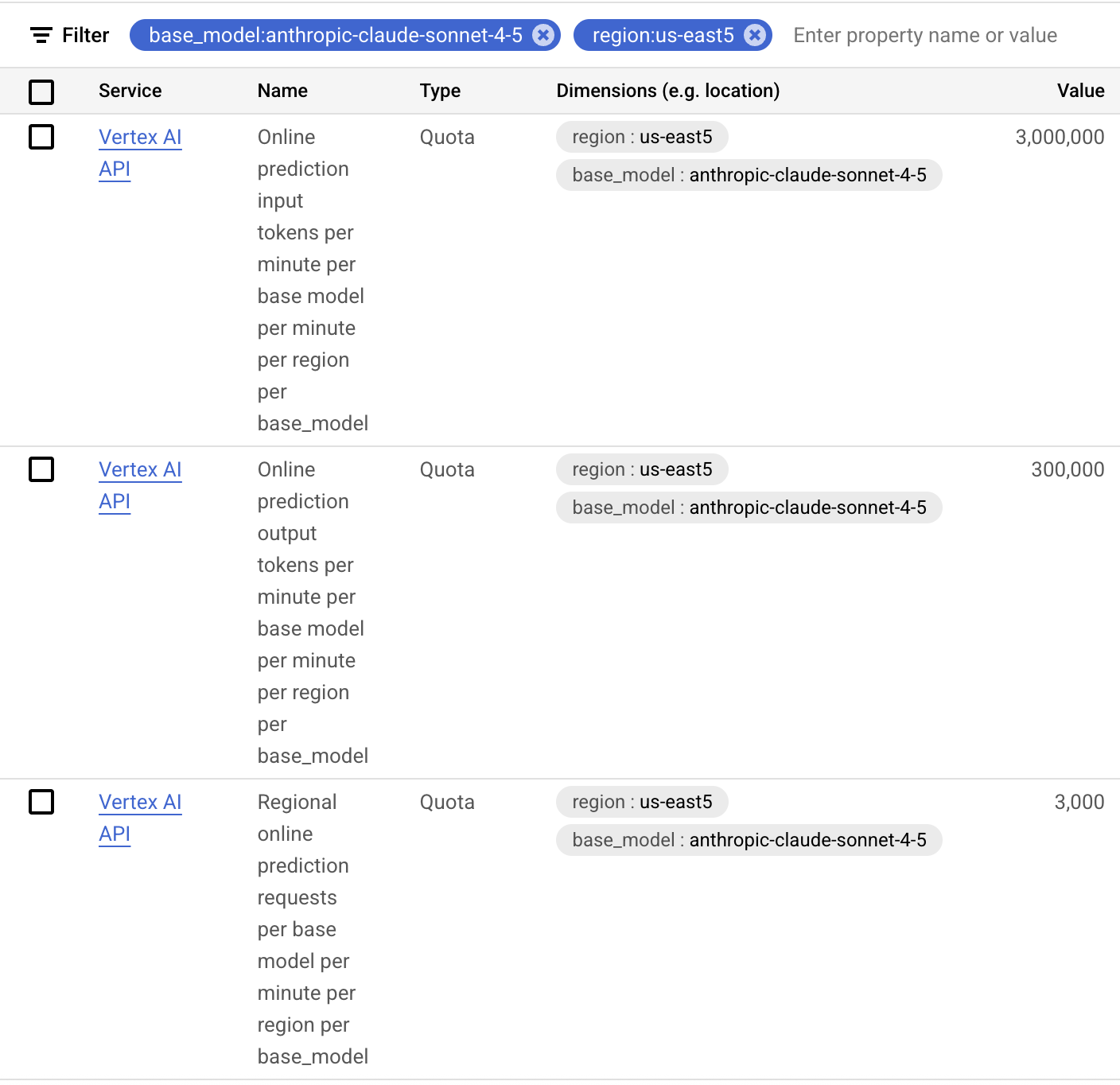
You will need to file a standard GCP quota request, which is expressed in Requests Per Minute (RPM) and Tokens Per Minute (TPM). Filter for base_model: on the model names in the table below and region: for the region that your GCP project is running in.
Please note that the quota is not a guarantee of capacity, but is intended by Google to ensure fair use of the shared capacity, and your requests may not be served during peak periods. To obtain guaranteed capacity, please speak with your Google account team about purchasing Provisioned Throughput.
Capacity Requirements
Glean token consumption varies based on query complexity and document size. To estimate your weekly LLM costs, calculate your expected weekly query volume and multiply by the per-query cost based on current Claude API pricing. Actual token usage will vary by customer depending on query complexity and document size.
To estimate throughput requirements (TPM), identify your deployment's query-per-minute (QPM) rate at the desired percentile (typically p90), then multiply by the average tokens per query.
The table below illustrates example TPM conversions assuming 0.004 QPM per DAU, based on historical customer data.
| Users | TPM |
|---|---|
| 500 | 125,000 |
| 1000 | 245,000 |
| 2500 | 615,000 |
| 5000 | 1,225,000 |
| 10000 | 2,450,000 |
| 20000 | 4,895,000 |
Glean highly recommends estimating capacity using your deployment's actual QPM to produce capacity estimates as QPM per DAU varies widely across customers.
Select the model in Glean Workspace
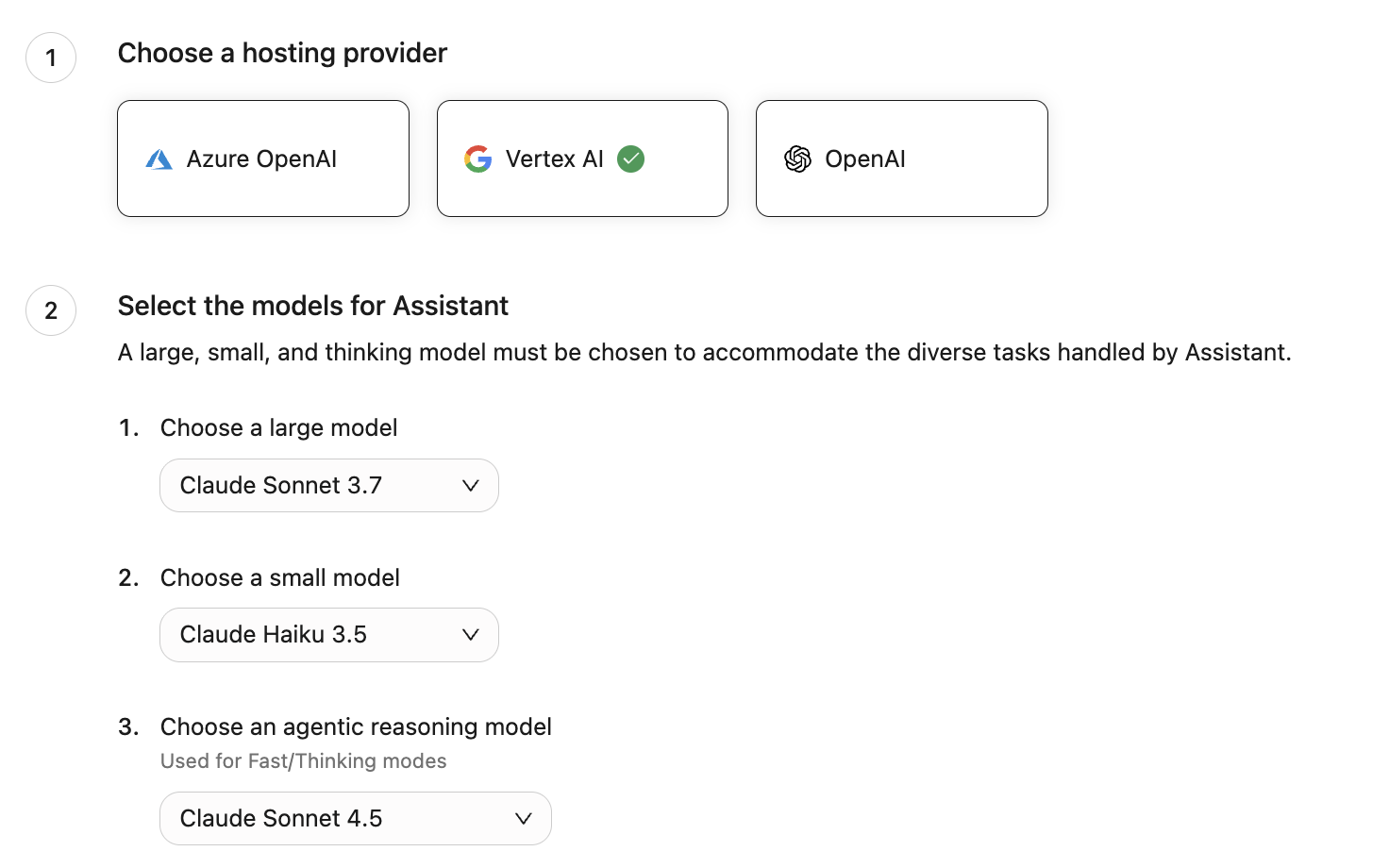
- Go to Admin Console → Platform → LLMs.
- Click on Add LLM.
- Select Vertex AI.
- Select Claude Sonnet 4.6 for the agentic model.
- Click Validate to ensure Glean can leverage the model.
- Once validated, click Save.
- In order to use Claude 4.6 Sonnet with Glean, agentic engine features should be turned on. See details here. Until these features are turned on, Glean will continue to use agentic and fast agentic models you previously configured. You do not need to change your agentic and fast agentic model at this time.
- We will use Application Default Credentials to call the models, so no additional authentication is required.
FAQ
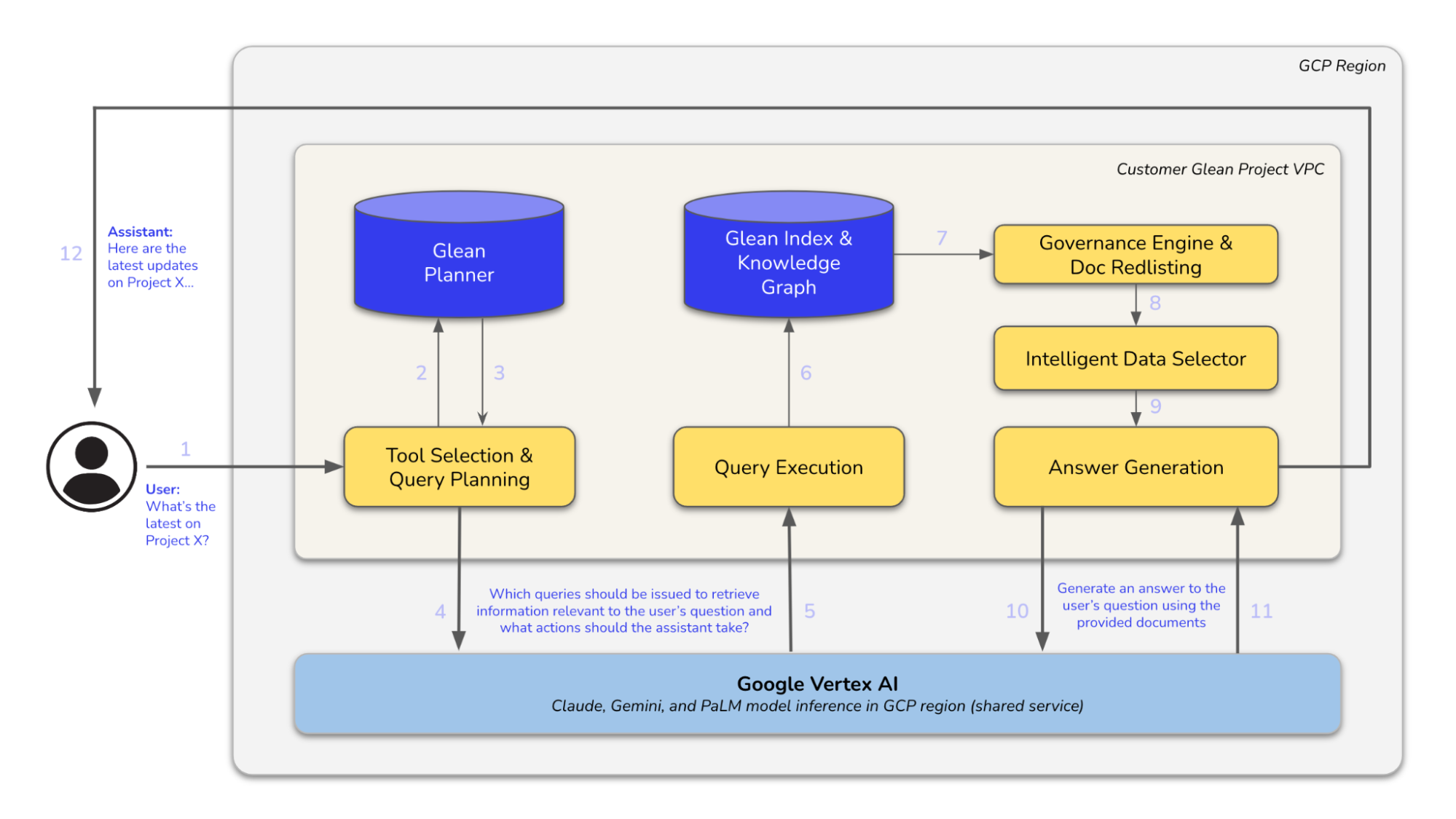
Architecture Diagram