Set up Glean with OpenAI GPT Models
This article provides instructions for customers hosted on GCP or AWS to configure Glean to use GPT models directly through their own OpenAI account for billing and capacity management.
Do not use this document if you are leveraging the Glean Key option. For the Glean Key option, Glean manages the configuration and provisioning of LLM resources transparently.
Enable access to models
Request access to the following models from the OpenAI Library:
| Model name | How Glean uses the model |
|---|---|
| GPT-5.1 (Preferred) | Agentic Reasoning model used in Fast and Thinking Modes in Chat. This is the primary model for Glean. |
| GPT-5 | Agentic Reasoning model used in Fast and Thinking Modes in Chat. This is the primary model for Glean. |
| GPT-5.1 | Agentic model used for other, more complex tasks in Glean |
| GPT-5.1 | Fast agentic model used for simpler tasks such as follow-up question generation |
Capacity for OpenAI Models
We highly recommend that you use priority processing from OpenAI. Priority processing will grant you faster, more consistent performance while getting the flexibility of a pay-as-you-go model. Here is the FAQ for priority processing.
Please check the OpenAI rate and usage limits for your organization. This can be found under Settings -> organization -> limits. Please ensure that you have the minimum capacity listed below, based on the number of users in your organization. Read more about the OpenAI tiers here.
Capacity Requirements for the latest assistant architecture on Agentic Engine 2 using GPT-5
| Users | High capacity model | Low capacity model | ||
|---|---|---|---|---|
| TPM | RPM | TPM | RPM | |
| 500 | 125000 | 10 | 5000 | 5 |
| 1000 | 250000 | 15 | 5000 | 5 |
| 2500 | 625000 | 35 | 10000 | 10 |
| 5000 | 1245000 | 65 | 15000 | 15 |
| 10000 | 2490000 | 130 | 30000 | 30 |
Select the model in Glean Workspace
- Go to Admin Console → Platform → LLMs
- Click on Add LLM
- Select OpenAI
- Select:
- GPT-5.1 (Preferred) or GPT-5 for the agentic engine model
- GPT-5.1 for the agentic model
- GPT-5.1 for the fast agentic model
- Click Validate to ensure Glean can leverage the model
- Once validated, click Save
Verify the model used by Glean
- Go to Glean and select the Public Knowledge Glean.
- Ask the question:
Who created you?
You should get a response similar to: I was created by OpenAI
FAQ
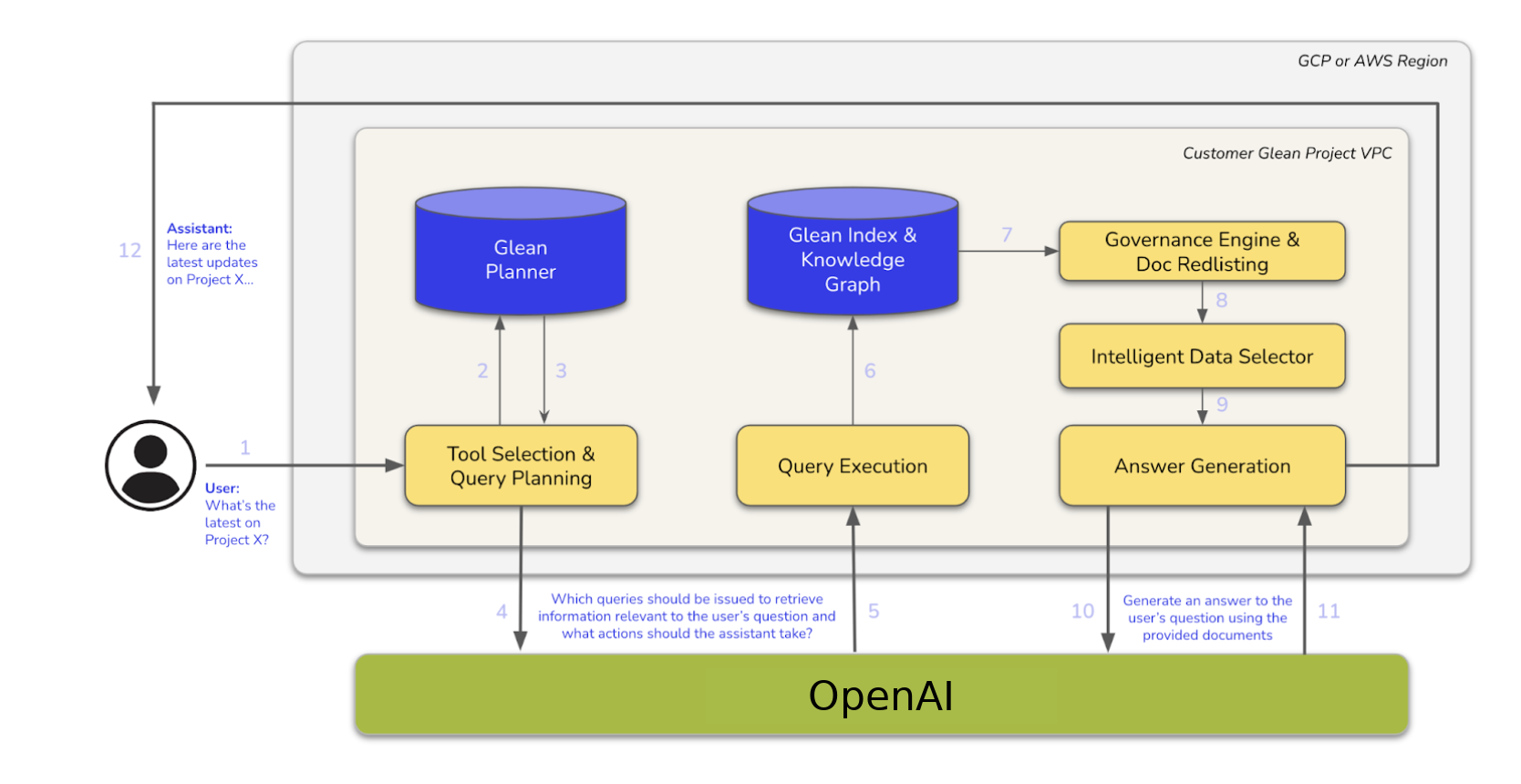
Architecture Diagram